Someone was partitioning an ancient laptop’s spinning rust, and asked where they should put their swap. At the start of the drive? At the end? As a swap file? Does it even matter?
While I’m on my 4th generation SSD at this point, I was interested enough to benchmark and find out. I would have used a swap file thinking it wouldn’t matter much, but boy was I wrong!
Test setup
My only remaining functional HDD — after putting two others in the electronics recycling bin — was a Western Digital 2.0TB WD20EARX SATA drive with 64MB cache.
I installed Ubuntu 21.04 Server on it, and partitioned it with 1G boot, 4G swap, 1.8T ext4 root, and another 4G swap. For easy testing, I did it all through kvm using the raw device without cache:
kvm -m 2048 -drive file=/dev/sda,format=raw,cache=none
I verified that the host did indeed not use its rather more generous RAM to cache the device.
The standard test, building Linux, did not swap as much as I hoped. With enough RAM to successfully boot, it didn’t really touch swap for as long as I bothered to watch it. I instead turned to my favorite RAM hog: building ShellCheck with the GHC Haskell compiler. This is a high RAM, low disk process.
I tried once with plenty of RAM, then each of the following with 2GB RAM and 4GB swap:
- Swap at the start of the drive
- Swap at the end of the drive
- Swap in a file created with
dd if=/dev/zero of=4g bs=1M count=4096(whichhdparm --fibmaprevealed to be allocated across four contiguous areas in the first 14GB of the device)
For fun, I also included:
- Swap on an old OCZ Vertex 4 SATA 256GB SSD
- Swap on my current Samsung 970 Evo Plus 1TB SSD
Each test was preceded by a git clean -fdx, swapoff/swapon, dropping caches, and finally a time cabal v1-build shellcheck.
I ran each test twice and picked the lowest number, though the variance was not large. For the swap file, I generated a second one to see if it was the luck of the allocator, but results were similar. dmesg showed no read errors after the tests finished.
Results
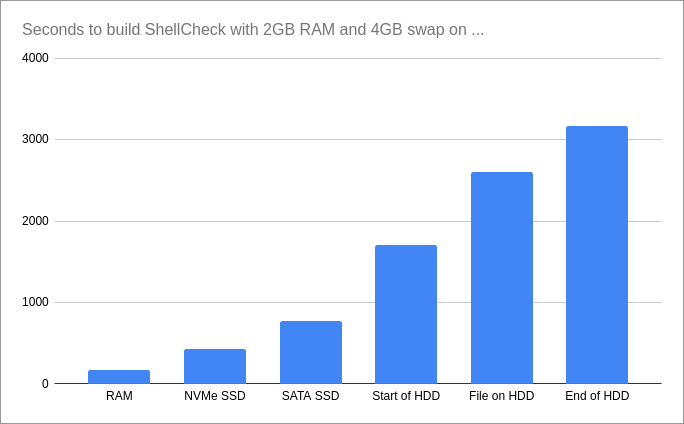
Or in numbers:
- 165s (2:45) — RAM only
- 451s (7:31) — NVMe SSD
- 771s (12:51) — SATA SSD
- 1701s (28:21) — Start of HDD
- 2600s (43:20) — Swap file on HDD
- 3161s (52:41) — End of HDD
In this test, using a swap file was surprisingly 50%+ slower than simply allocating a swap partition at the start of the drive, in spite of the low fragmentation and Linux’s bypass of the FS layer.
Drives and workloads obviously vary, but if nothing else we can safely say that yes, placement matters.
